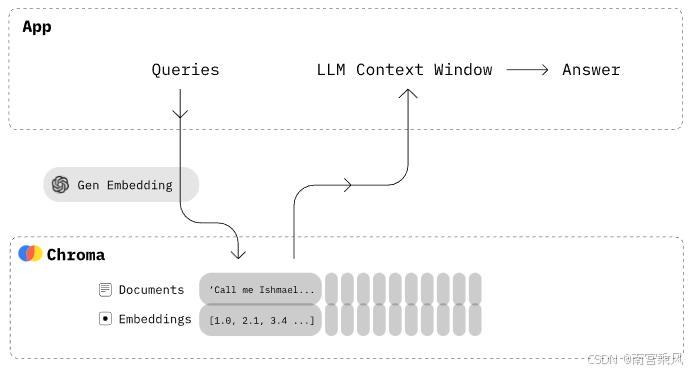
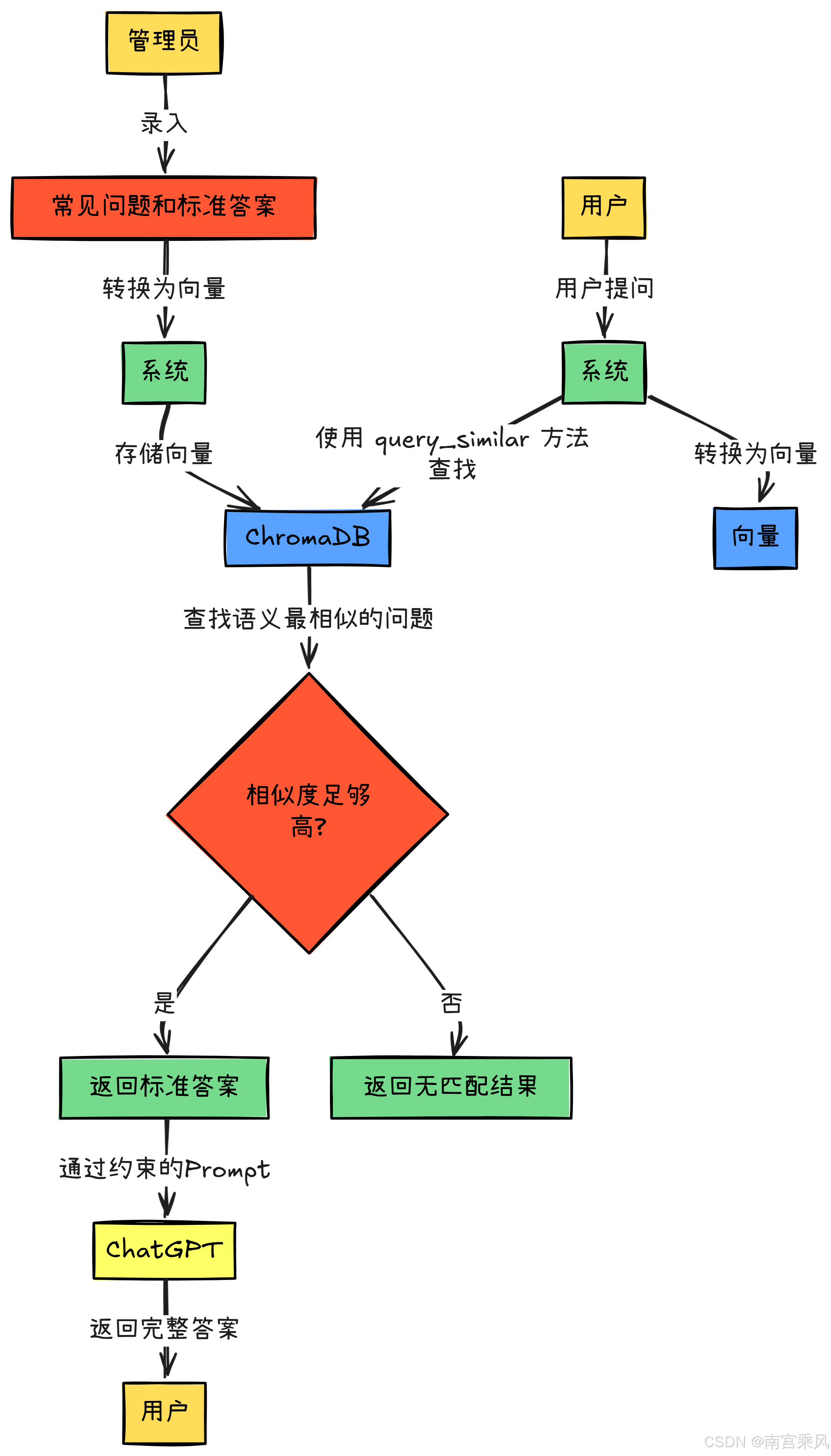
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
|
import hashlib
import os
from datetime import datetime
from pathlib import Path
from typing import Optional, Tuple
import chromadb
from chromadb.config import Settings
from embedding_client import get_embedding_client
from utils.LogHandler import log
class ChromaClient:
def __init__(self, persist_directory: str = None):
"""
初始化Chroma客户端
:param persist_directory: 持久化存储路径,默认为项目根目录下的chroma_db
"""
if persist_directory is None:
# 获取项目根目录
root_dir = Path(__file__).parent.parent
persist_directory = os.path.join(root_dir, "chroma_db")
# 确保目录存在
os.makedirs(persist_directory, exist_ok=True)
# 修改初始化设置
self.client = chromadb.PersistentClient(
path=persist_directory,
settings=Settings(
anonymized_telemetry=False,
is_persistent=True # 显式指定持久化
)
)
# 创建或获取集合
self.collection = self.client.get_or_create_collection(
name="kefu_qa",
metadata={"hnsw:space": "cosine", "description": "客服问答向量库"}
)
self.embedding_client = get_embedding_client()
from utils.LogHandler import log
log.info(f"ChromaDB initialized at: {persist_directory}")
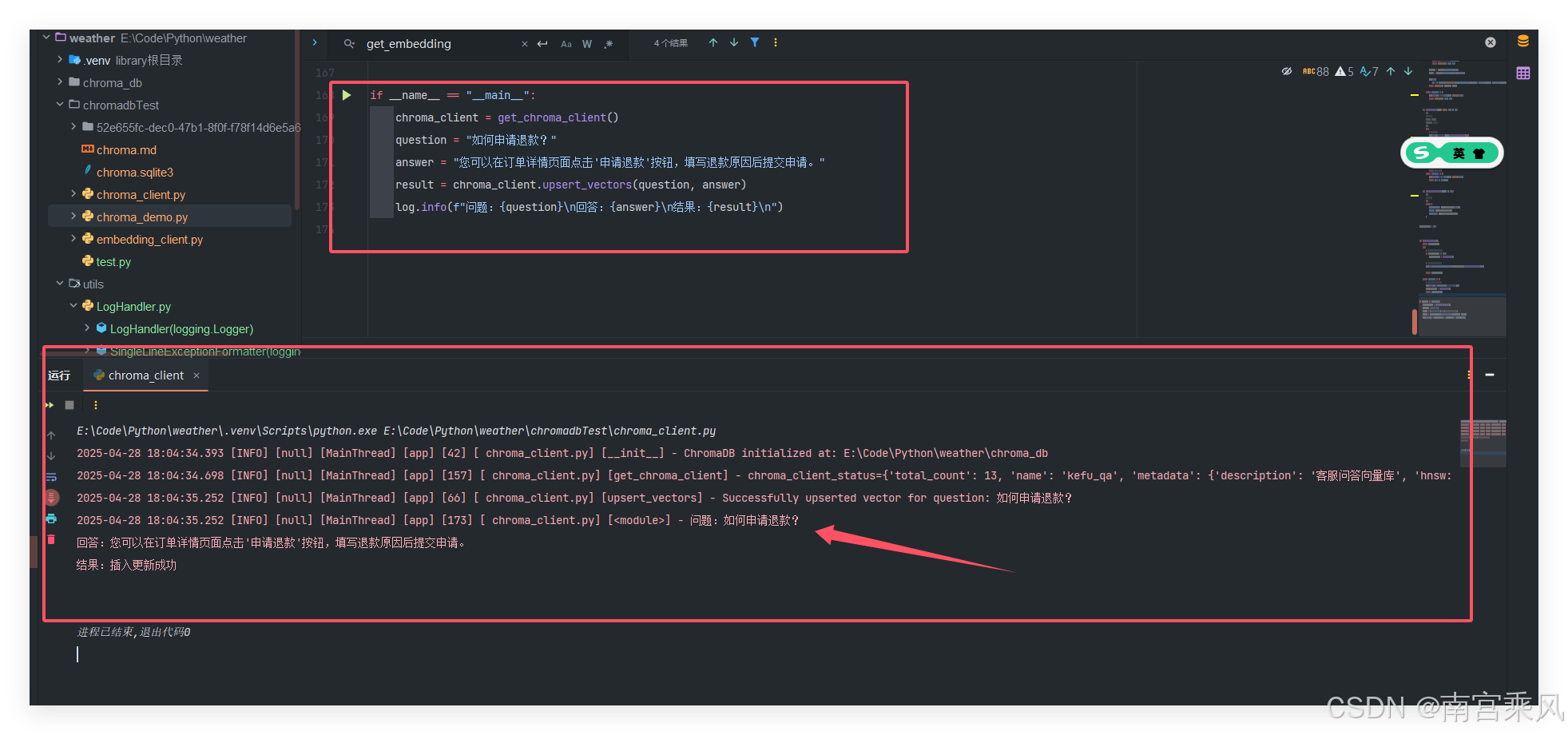
def upsert_vectors(self, question: str, answer: str) -> str:
"""
插入或更新向量
:param question: 问题文本
:param answer: 答案文本
:return: 操作结果信息
"""
qhash = hashlib.md5(question.encode('utf-8')).hexdigest()
try:
embedding = self.embedding_client.get_embedding(question)
metadata = {
"answer": answer,
"timestamp": datetime.now().isoformat()
}
self.collection.upsert(
ids=[qhash],
embeddings=[embedding],
documents=[question],
metadatas=[metadata]
)
log.info(f"Successfully upserted vector for question: {question}")
return "插入更新成功"
except Exception as e:
log.error(f"向量更新失败: {str(e)}", exc_info=True)
return f"向量更新失败: {str(e)}"
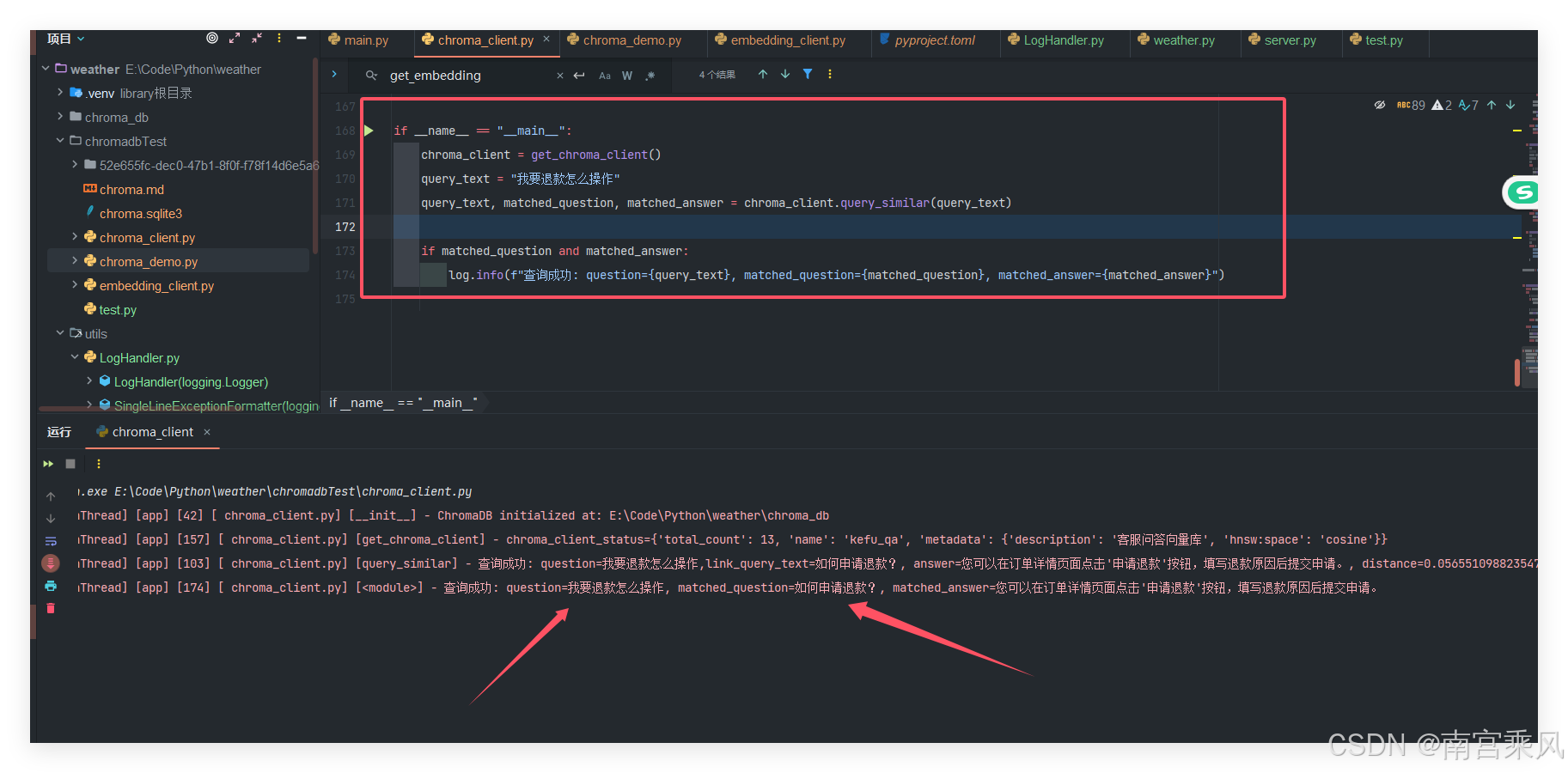
def query_similar(self, query_text: str, top_k: int = 1) -> Tuple[str, Optional[str], Optional[str]]:
"""
查询相似向量
:param query_text: 查询文本
:param top_k: 返回结果数量
:return: (查询文本, 匹配问题, 匹配答案)
"""
try:
query_embedding = self.embedding_client.get_embedding(query_text)
results = self.collection.query(
query_embeddings=[query_embedding],
n_results=top_k,
include=["documents", "metadatas", "distances"],
where=None, # 可选的过滤条件
where_document=None # 可选的文档过滤条件
)
# 检查结果是否为空
if not results['ids'] or not results['ids'][0]:
log.info(f"未找到匹配问题:{query_text}")
return query_text, None, None
# 获取相似度分数
distance = results['distances'][0][0]
if distance > 0.4: # 相似度阈值,可根据需要调整
log.info(f"找到的匹配相似度过低:{distance}")
return query_text, None, None
question = results['documents'][0][0]
answer = results['metadatas'][0][0]['answer']
log.info(
f"查询成功: question={query_text},link_query_text={question}, answer={answer}, distance={distance}")
return query_text, question, answer
except Exception as e:
log.error(f"查询失败: {str(e)}", exc_info=True)
return query_text, None, None
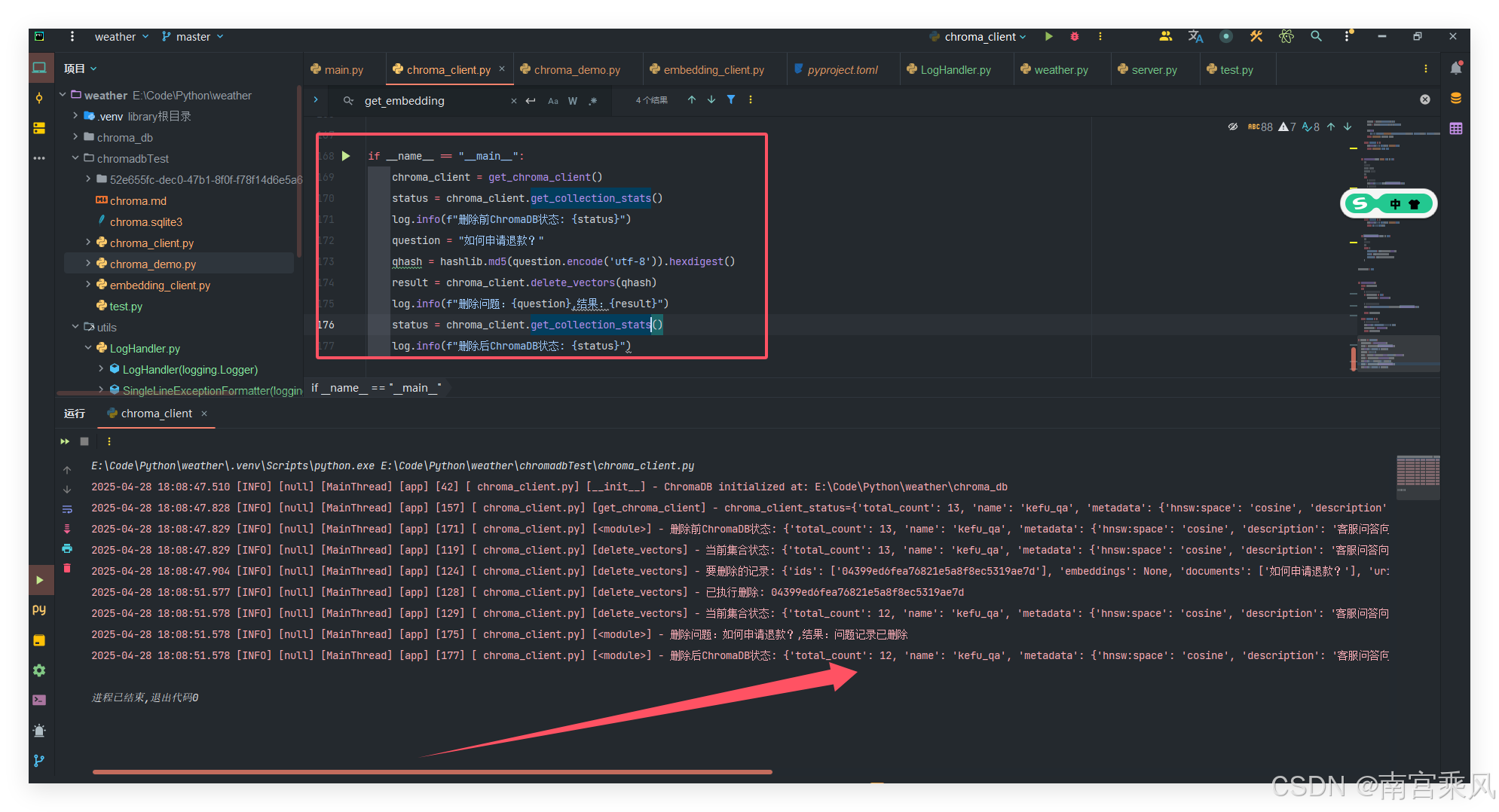
def delete_vectors(self, qhash: str) -> str:
"""
根据问题删除向量
:param qhash:
:return: 删除结果信息
"""
try:
# 先检查集合中的数据
log.info(f"当前集合状态: {self.get_collection_stats()}")
# 尝试获取要删除的记录
existing = self.collection.get(
ids=[qhash]
)
log.info(f"要删除的记录: {existing}")
self.collection.delete(
ids=[qhash]
)
log.info(f"已执行删除: {qhash}")
log.info(f"当前集合状态: {self.get_collection_stats()}")
return "问题记录已删除"
except Exception as e:
log.error(f"删除失败: {str(e)}", exc_info=True)
return f"删除失败: {str(e)}"
def get_collection_stats(self) -> dict:
"""
获取集合统计信息
"""
return {
"total_count": self.collection.count(),
"name": self.collection.name,
"metadata": self.collection.metadata
}
_chroma_client = None
def get_chroma_client():
global _chroma_client
try:
# 如果是第一次创建,或者需要重新检查状态
if _chroma_client is None:
_chroma_client = ChromaClient()
# 获取集合统计信息进行更详细的状态检查
log.info(f'chroma_client_status={_chroma_client.get_collection_stats()}')
return _chroma_client
except Exception as e:
# 如果出现任何异常,记录日志并重新创建
log.error(f"获取ChromaClient失败,重新创建对象: {e}")
_chroma_client = ChromaClient()
return _chroma_client
if __name__ == "__main__":
chroma_client = get_chroma_client()
stats = chroma_client.get_collection_stats()
print(f"删除前的集合统计: {stats}")
|